OCR vs ICR: What’s the Difference?

The days of manually transcribing scanned documents into an editable, digital document are thankfully long behind most organizations. Error-prone manual processes have largely given way to automated document and forms processing technology that can turn scanned documents into a more manageable form with a much higher degree of accuracy.
Much of transition was made possible by the proliferation of optical character recognition (OCR) and intelligent character recognition (ICR). While they perform very similar tasks, there are some key differences between them that developers need to keep in mind as they build their document and form processing applications.
How Does Character Recognition Technology Work?
Character recognition technology allows computer software to read and recognize text contained in an image and then convert it into a document that can be searched or edited. Since the process involves something that humans can do quite easily (namely, reading text), it’s easy to assume that this would be a rather trivial task for a computer to accomplish.
In reality, getting a computer program to correctly identify text and convert it into editable format is an incredibly complex challenge complicated by a wide range of variables. The problem is that when a computer examines an image, it doesn’t see people, backgrounds, or text as distinct images, but rather as a pattern of pixels. Character recognition technology helps computers distinguish text by telling them what patterns to look for.
Unfortunately, even this isn’t as straightforward as it sounds. That’s because there are so many different text fonts that depict the same characters in different ways. For example, a computer must be able to recognize that each of the following characters is an “a”:
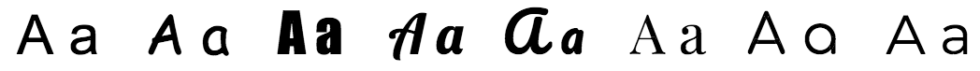
When humans read text, they have a mental concept of what the letter “a” looks like, but that concept is incredibly flexible and can easily accommodate a broad range of variations. Computers, however, require precision. Programmers must provide them with clear parameters that help them to navigate unexpected variations and identify characters accurately.
Pattern Recognition
The earliest versions of character recognition developed in the 1960s relied on pattern recognition techniques, which scanned images and searched for pixel patterns that matched a backlog of font characters stored in memory. Once those patterns were located, the software could translate the characters into searchable, editable text in a document format. Unfortunately, the patterns had to be an exact pixel match, which severely limited how broadly the technology could be applied.
One of the first specialized fonts developed to facilitate pattern recognition was OCR-A. A simple monospace font (meaning that each character has the same width), OCR-A was used on bank checks to help banks quickly scan them electronically. Although pattern recognition libraries expanded over the years to incorporate common print fonts like Times New Roman and Arial, this still presented serious limitations, especially as the variety of fonts continued to grow. With one popular font finding website indexing more than 775,000 available fonts in 2021, pattern recognition needed to be supplemented by another approach to character recognition.
Feature Detection
Also known as feature extraction, feature detection focuses on the component elements of printed characters rather than looking at the character as a whole. Where pattern recognition tries to match characters to known libraries, this approach looks for very specific features that distinguish one character from another. A character that features two angular lines that come to a point and are crossed by a horizontal line in the middle, for instance, is almost always an “A,” regardless of the font used. Feature detection focuses on these qualities, which allows it to identify a character even the program has never encountered a particular font before. As the printed examples above demonstrate, however, this approach needs to take several ways of rendering the character “A” into consideration when setting parameters.
Most character recognition software tools utilize feature detection because it offers far more flexibility than pattern recognition. This is especially valuable for reading document images with faded ink or some degradation that could prevent an exact pattern match. Feature detection provides enough flexibility for a program to be able to identify characters under less than ideal circumstances, which is important for any application that has to deal with scanned images.
OCR vs ICR: What’s the Difference?
Optical character recognition (OCR) is typically understood to apply to any recognition technology that reads machine printed text. A classic OCR use case would involve reading the image of a printed document, such as a book page, newspaper clipping, or a legal contract, and then translating the characters into a separate file that could be searched and edited with a document viewer or word processor. It’s also incredibly useful for automating forms processing. By zonally applying the OCR engine to form fields, information can be quickly extracted and entered elsewhere, such as a spreadsheet or database.
When it comes to form fields, however, information is frequently entered by hand rather than typed. Reading hand-printed text adds another layer of complexity to character recognition. The range of more than 700,000 printed font types is insignificant compared to the near infinite variations in hand-printed characters. Not only must the recognition software account for stylistic variations, but also the type of writing implement used, the quality of the paper, mistakes, steadiness of hand, and smudges or running ink.
Intelligent character recognition (ICR) utilizes constantly updating algorithms to gather more data about variations in hand-printed characters to identify them more accurately. Developed in the early 1990s to help automate forms processing, ICR makes it possible to translate manually entered information into text that can be easily read, searched, and edited. It is most effective when used to read characters that are clearly separated into individual areas or zones, such as fixed fields used on many structured forms.
Both OCR and ICR can be set up to read multiple languages, although limiting the range of expected characters to fewer languages will result in more optimal recognition results. Critically, ICR does not read cursive handwriting because it must still be able to evaluate each individual character. With cursive handwriting, it’s not always clear where one character ends and another begins, and the individual variations from one sample to another are even greater than with hand-printed text. Intelligent word recognition (IWR) is a newer technology that focuses on reading an entire word in context rather than identifying individual characters.
To learn more about how OCR vs ICR technology and how they can transform your application when it comes to managing documents and automated forms processing, download our whitepaper on the topic today.
Share This Article