Technical FAQs

Rick Scanlan, Accusoft Director of Sales Engineering
Throughout time people have been looking for ways to gather information. The invention of the printing press allowed large-scale production of documents and printing of the earliest forms. Until the 1980s, information collected from forms was tabulated by hand or manually entered into a computer. Hand print recognition technology, more commonly known as Intelligent Character Recognition (ICR), has progressed significantly since that time, but the accuracy and productivity of forms processing is highly dependent on form design.
There are many factors to consider when designing a form to collect hand printed responses. First and foremost, the form needs to be easily understood by your target audience. The form also needs to constrain the response area and clearly identify where the user should write their responses.
Remember that the person filling out the form is usually out of your control. No matter how well you design your form, there will always be responses that can’t be read automatically. You can encourage the form fillers to write neatly, and keep their responses within the spaces allotted, but there will always be people who don’t read instructions (or ignore them) and assume that the form will be read by a human, not by a computer. They may do things like writing a character by mistake, then drawing a big “X” over it to “delete” it. Some people have poor handwriting, or always write in cursive.
Accuracy vs Confidence
Although they’re often used interchangeably, “accuracy” and “confidence” have two different meanings with regards to ICR software. Accuracy represents the percentage of actual text that is read correctly. Since character recognition applications don’t actually know when they misread a character, they cannot self-report accuracy. It can only be calculated after the recognition process by comparing the “ground truth” (the actual text) with the application’s reported recognition results.
“Confidence,” on the other hand, represents how certain the application is that it has identified a character correctly. Each character result generally has a confidence value ranging from 0 to 100, which can be calculated based upon a variety of recognition characteristics. Confidence values can also be returned for each line of characters or each field in a form in addition to each character individually.
If the ICR engine’s confidence does not exceed this value when reading a given character, it may reject the character and replace its text output with a placeholder until it can be reviewed manually. This is typically done when the engine is unable to determine what a pattern of pixels represents. Some engines (such as Accusoft’s SmartZone) can instead be configured to report the character result with the highest confidence or return a list of possible characters, each with individual confidence values. A final determination can then be made through human review or other data validation operations.
The industry accuracy average for ICR applications is about 70%. That means that three out of every ten characters are read incorrectly or aren’t recognized with a high enough confidence to be considered accurate. One should never expect 100% accuracy in any forms processing project, but a successful ICR application should exceed 70% accuracy. A rate of 85% or higher is considered good (although that’s still 15 bad characters out of every 100). With a little planning and some basic form design elements in place, however, you can usually exceed the 70% threshold.
In fact, since the way people fill out your forms has such a big impact on recognition results, taking small steps to improve compliance is immensely beneficial. Without changing any other aspects of your form, simply changing user instructions can provide a significant improvement in recognition rates.
5 Simple Ways Improve ICR Software Recognition Rates
- Tell the user that the form will be processed by a computer.
- Stress the importance of writing plainly, carefully, and clearly.
- Ask them to use block letters and avoid cursive handwriting.
- Put the instructions in bold at the top of the form, or just above the first field.
- Show character examples such as how an “A” or a “2” should be formed.
Field Design Considerations for ICR Software
Properly laying out the areas for printed responses can make the most significant impact in accurate hand print content recognition. A common mistake in field design is to provide a freeform area for a response. This design is often a simple blank line where people should write. Without any character restraints, people will write in cursive, run their characters together, write on top of the line, or write multiple lines in a single line response area. All of these factors will have a serious impact on intelligent text recognition accuracy.
A form needs to have a defined response area for each character, encouraging character separation. Some approaches for character separation work better than others, and are described below.
Comb Lines
Comb lines are horizontal lines with small vertical separators called tick marks. This is traditionally the most common type of hand print form design, often used in manual data entry applications. However, it’s not as well suited for automated ICR processing as other approaches. While the tick marks may encourage people to separate their characters, they rarely ever write the characters within each space. The spacing between the vertical lines on many forms is frequently too close together, making it almost impossible for the average person to stay between the lines. The height of the tick lines also plays an important role in encouraging character separation.
If you use comb lines, provide plenty of room between each of the vertical tick marks. Make the tick marks tall enough to encourage people to write between them. A vertical height at least half the height of the expected character is usually sufficient.
Example of a Poor Comb Line

Example of a Good Comb Line
Character Boxes
Character boxes are usually the best method to encourage character separation. A good character box design will allow users to write their characters completely within each box. Unfortunately, many forms contain boxes that are too small and too close together. People often can’t write small enough to keep an entire character within a box. Pencil lead creates strokes that are usually much wider than with pens, making it even harder to constrain the character. The following are some general guidelines for designing character boxes.
Each box should be square in shape. Rectangular boxes with the height taller than the width can make the user feel like they need to squeeze their characters into the space. This often results in characters written in a compressed vertical form, reducing accuracy. A square shape encourages wider, more normally formed characters.
Narrow Boxes

Square Boxes

Single character response locations, such as for Male (“M”) or Female (“F”), should be provided in a single box separated from other responses.
Multiple character response locations, such as a Name field, may contain separated boxes if space permits.

They could also be joined together when space is a consideration. If joined, a thick separator between the response locations, at least one-fourth the width of a response area, should be used to discourage characters entering other boxes.

Individual fields should be separated by enough space to easily identify where one field stops and the next starts. Spacing of at least 1.5 box widths is recommended to prevent users from interpreting the space as a valid character location.

Rows of fields stacked vertically should be separated by at least one half the height of an individual box.

Boxes can be printed with either solid black lines or dropout colors, depending on the scanning and forms processing technology used. Some forms processing technology, such as Accusoft’s FormSuite software development kit (SDK), best performs form identification and alignment when all boxes and form contents are retained. Software-based form dropout is used to remove the boxes from the image after scanning. The original image with boxes intact may then be archived for future reference.
Several forms processing systems require dropout colors to be used when printing forms. For example, a form is printed in red ink, and a red bulb in the scanner eliminates the red content when the image is captured. Unlike these types of forms processing technology, the FormSuite SDK doesn’t require any special printing, paper, or inks. It provides much greater printing flexibility and reduced printing costs. The use of general purpose scanning technology without requiring special bulbs may also reduce capital costs.
Paper Thickness and Bleed-Through
The quality of paper can impact recognition accuracy in dual-sided forms. Form paper should be thick enough to prevent the back side content from bleeding through when scanned. Fields on form fronts and backs may also be offset to ensure that any bleed-through content from one side will not interfere with field recognition on the other.
Example of Bleed Through

Processing a Hand Print Form
Intelligent character recognition accuracy can often be increased through image enhancement and other pre-processing activities. Many scanners today include image enhancement technologies that will create a good representation of the original image. This enhanced image may work well for viewing or archival purposes, but it may not be the best to use for content recognition. Lines or boxes in the image may interfere with field recognition. Dot shaded fields may prevent easy recognition of filled content. Filled forms might be received via fax at a low resolution, where built-in image enhancement is not available. The use of post-scan image enhancement processes can significantly improve forms processing and intelligent text recognition.
A temporary copy of the image can be created solely for use with the ICR application. Enhancements are performed that directly impact recognition. If poor recognition results are received, additional enhancements may be performed, looping through a series of “enhance – attempt to recognize – enhance – attempt to recognize” processes until the field is read with high confidence or a decision is made to route the image for manual data entry. Once recognition is complete, the temporary image is deleted and the original image is archived.
Certain enhancement processes are specifically designed to improve character recognition, especially when you don’t have control over the form design. For example, forms that contain shaded fields in response areas can be very difficult to recognize. Dot shading removal with character smoothing can significantly improve recognition of those fields.
Software-based form dropout—removal of background form content—can allow recognition of content that has been written over master form elements. For example, users completing forms with comb lines often write on top of the lines, resulting in very difficult recognition. An automated comb line removal process will remove the comb lines and reconstruct the intersecting characters, allowing for accurate recognition.
Before Comb Removal
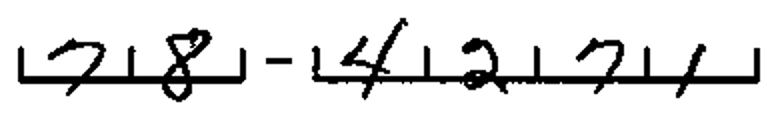
After Comb Removal, with Character Repair
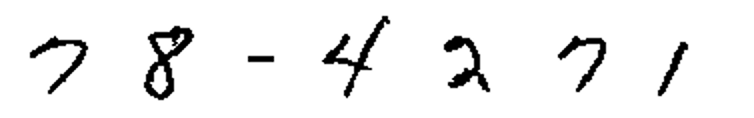
Improve ICR Application Performance with Focused Recognition and Data Validation
Some fields are designed to allow only certain characters to be entered. For example, a date field may allow only digits, or only digits, dashes, and slashes. A “Male/Female” field may only allow the characters M and F. Ensure that your form contains instructions or examples for each field to ensure the user knows what characters are allowed. ICR technology such as Accusoft’s SmartZone ICR/OCR component allows definition of allowable characters, increasing accuracy by focusing the recognition engine towards specific characters.
Remember that the industry average for hand print recognition is only 70%. Data validation and correction is critical to a successful hand-printed forms recognition system. Use recognition confidence values to locate suspect characters. Use two or more ICR engines in a voting process, comparing the results from each engine to determine the highest confidence results. Recognized data should be compared against database tables, dictionaries, lookup tables, or other data validation tools.
A “key from image” process is typically required to validate low confidence data. You should develop a process to display suspect characters or fields to a human for manual data entry. Human interaction is the most expensive part of any data capture process, so any efforts you can take, such as strong form design or additional image enhancement processes, will easily pay for themselves when compared to the cost of manual data entry.
Test Your Form
It’s critical to develop a prototype of your form then test it on a sampling of actual users. Present the form to people who have not seen any previous versions and ask them to complete it. Statistical sampling and analysis is helpful when testing forms that will be used on a large scale. Forms for smaller audiences do not require scientific analysis. Just be sure that you employ representative users in the test.
You should also test your recognition processes with enough sample data to get a good sense of the results. Identify weaknesses in the form or recognition, make changes, then retest to confirm improved results.
A Note About OMR
Optical Mark Recognition (OMR), sometimes known as “mark sense,” is the analysis of form locations to determine if a mark is present. Examples of OMR zones include check boxes on a form to designate male or female, multiple choice responses on a high-stakes educational exam, or diagnosis results on a medical form. The OMR response areas may be a single box, multiple response zones such as a “check all that apply” field, or a true/false designation.
Many forms contain some type of OMR field. Designing an OMR field is simpler than for character recognition, but still requires careful consideration. Whether you use an oval bubble, square box, or open brackets, be sure the area is large enough for the user to easily mark within the designated space.
Common OMR field design errors include making the box too small for people to easily mark within the zone, or printing the boxes too close together, resulting in more than one box containing the mark. Some users will circle an OMR response area instead of filling in the box. Similar to character responses, providing clear instructions and example marks can significantly improve recognition results. Even great instructions will not prevent some people marking a zone in error then drawing a big “X” over in an attempt to “delete” the mark. Business rules must be developed to handle multiple mark situations and manual key-from-image operations are usually required to determine user intent.
In Conclusion
Many factors influence the accuracy and success of a hand print forms processing system. The extra time and consideration spent in forms design will pay strong dividends in recognition accuracy and reduced costs for manual data entry. Carefully consider your target audience to design a form that will be easily understood and completed, and can be easily recognized and processed by ICR software.
Rick Scanlan joined Accusoft with the acquisition of TMSSequoia in December 2004. With 27 years of experience in the document imaging market, Rick has served in a variety of technical, business development, and corporate management roles. He has developed extensive expertise in a wide variety of imaging technologies including document viewing, information capture, image enhancement, and forms processing. Rick currently manages Accusoft’s sales engineering/pre-sales team and helps define Accusoft’s product strategy and future development. A native of Oklahoma, he earned Bachelor of Science degrees from Oklahoma State University in Business Management, Economics, and Management Science and Computer Systems.

Image processing is now a priority across industry lines. From legal firms to financial institutions to health organizations the ability to capture, convert, and combine documents on-demand often makes the difference between hitting project deadlines and falling behind.
As image formats outpace the ability of legacy solutions to manage and manipulate, however, a new challenge emerges. Companies need conversion, document management, and image cleanup software capable of handling multiple file types, but are they better served building their own systems or buying software solutions to help them bridge the gap? Let’s go head-to-head and see which potential processing option comes out on top.
Round One: Targeting Consistency
Ask companies why they prefer to build their own software solutions and the answer is invariably the same, control. The work of creating new functionality from scratch is often paired with the notion of end-to-end control; since in-house developers built the image processing program they’re equipped to handle any emerging security or performance challenges.
The problem? In a world where robust digital solutions are the expectation rather than the exception, speed and consistency are the image-processing benchmarks. Staff need to know that when they go looking for image conversion and document management options, they’ll always find exactly what they’re looking for — and it will always perform as expected.
In-house options that require regular maintenance and security updates can’t match this level of accessibility; ensuring optimal performance demands regular downtime to both implement planned updates and deal with potential problems as they occur. Fully-supported, purpose-built processing solutions, meanwhile, deliver consistent results and common functionality on-demand.
Round Two: Talking Conversion
The biggest benefit of image processing software? Conversion. The ability to intake documents and easily modify their format, adjust properties, or add essential changes. Here, building your own image processing engine comes with the benefit of specificity. If you’re dealing primarily with PDF files, create a small-scale PDF library capable of handling PDFs and turn it loose across internal networks.
Here’s where things get tricky. While introducing a new, purpose-built application solves one problem, it also creates another: app overload. As noted by recent workplace research, almost 70 percent of workers already lose up to 60 minutes per day navigating between different software solutions. Adding a new in-house tool lets them avoid searching online for a functional best-fit but also adds another app to their list and increases their total time wasted. On the developer side, building comes with the ongoing time and resource commitments necessary to create and support multiple imaging libraries — and keep up with the ongoing evolution of new image file formats.
Image processing software development kits (SDKs), meanwhile, come with conversion abilities across a host of file types. Even better? These tools integrate with existing solutions, meaning your team gets the advantage of easy image conversion without the added complication of constantly switching apps.
Round Three: Taking the Shortcut
There’s an understandable pride that comes with building apps from the ground up. In many respects, buying a software engine seems like taking a shortcut. But here’s the thing, shortcuts are faster. Even if you were designing an app from scratch, your developers would search popular code repositories to avoid repeating work someone else has already done. After all, if a great image processing tool already exists, why build another?
Image processing SDKs simply scale up the scope of common code usage to streamline your document management, conversion, and image cleanup processes. As noted by DZone, there’s also a case here for compatibility; by laying customizable software engines on top of existing applications, you ensure that desktop, mobile, and even remote users all have access to the same functionality.
Building your own image processing program is entirely possible if you like heavy lifting, enjoy total control, and hate taking shortcuts. However, buying a full-featured engine capable of handling multiple file types across any enterprise endpoints is the ideal approach if you’re looking for ease of integration, consistent compliance outcomes, and company-wide compatibility. Learn more about ImageGear and all of its capabilities here.

Powerful patient portals are now essential for healthcare organizations to deliver high-quality care, even at a distance. Despite advancements around functionality, however, challenges remain. As noted by Healthcare Info Security, many healthcare providers still struggle with providing solutions to patients in an easily accessible portal that provides the security they require by law.
Here, HIPAA compliance is critical. Healthcare organizations need portal solutions that deliver valuable information without undermining regulatory requirements around data security and handling. Creating innovative, secure patient portals demands HIPAA-compliant tools that deliver advanced viewing and redaction tools while keeping privacy in practice.
The State of Healthcare Security
Security remains a problem for healthcare organizations as attackers ramp up efforts to access private patient and operational information. The healthcare industry saw more than 41 million records breached in 2019 and new attack vectors are now emerging as hackers look to leverage pandemic pressures and breach corporate security. It’s no surprise, then, that last year saw 28,261 HIPAA complaints, the highest number ever recorded, as organizations deployed more user-friendly technology and attackers looked to capitalize on potential weaknesses.
Ramping up security in patient portals and meeting emerging patient needs is a priority for organizations. Accusoft’s PrizmDoc Cloud, a HIPAA compliant solution, is capable of offering user-friendly portal capabilities inside your own secure application. The right combination of existing technology and cloud-based application programming interfaces (APIs) can take your patient portal to the next level. Let’s break down five key cloud-based APIs that can help patient portals deliver on practical potential.
Robust Document Viewing with PrizmDoc Cloud API
Effective medical care depends on documents. From patient consent forms to test results and referrals from other healthcare practices, documents form the core of custom-built treatment plans. While the transition to electronic health records (EHRs) has helped reduce the complexity and confusion that comes with paper-based processes, this digital transition has introduced the challenge of document diversity.
From typical Word documents to Excel spreadsheets and scanned images of handwritten forms, patients need the ability to access documents on-demand, while healthcare organizations must ensure that patient access options are both secure and HIPAA-compliant.
The PrizmDoc HTML5 Document Viewing API offers document and image viewing while also streamlining the process with key features including:
- Responsive Web UI — Patients and staff can easily view documents and images that are scaled to fit their tablet, laptop, or mobile phone.
- Configurable Controls — Organizations can easily enable or disable tabs, localization, rendering options, and encryption within their patient portal.
- Microsoft Office (MSO) Conversion — Healthcare agencies can integrate true native viewing of Word, Excel, and PowerPoint documents.
Reliable PII Redaction
Data privacy is paramount for HIPAA compliance. As noted by Managed Healthcare Executive, this is especially critical in the world of COVID-19. With telehealth now the “new normal” — and likely to continue long after the pandemic subsides — organizations must ensure that protection of personally identifiable information (PII) remains intact.
While robust encryption and identity access management (IAM) tools form part of this function, redaction is another critical aspect. Consider the case of children. As noted by the Health Info Security piece, although parents typically have complete access to the medical records of children under 12, PII for those between the ages of 13 and 18 — such as mental health records — may be restricted. For healthcare agencies, this requires patient portal solutions that allow parents access to some data while also protecting specific PII. Here, robust redaction APIs that allow organizations to obfuscate key information are critical to meet regulatory requirements without compromising ease-of-access.
Regulated Image Compression
Images form a critical component of effective patient prognosis and treatment plans, and while DICOM files used in high-fidelity imaging are often a priority for medical agencies, there’s also a need for image compression solutions that enable the portability of more common image types such as JPEGs.
Consider the simple case of patient identification. By attaching high-quality photos to patient records, medical staff are better equipped to ensure the individual they’re assisting — virtually or in-person — is the patient linked to the account. High-quality JPEG photos are also useful to record and track the progress of specific physical ailments over time. Cloud-based image compression APIs streamline this process with the ability to compress individual or multiple files, set desired quality, remove metadata, and set JPEG mode output.
Rapid File Conversion
Complexity remains a challenge for healthcare records management. As patients visit general practitioners (GPs) and specialists, data volumes rapidly increase, in turn making it difficult for doctors to find specific information and create comprehensive treatment plans.
Multi-file combination and conversion to popular formats such as PDF helps solve this problem — not only can healthcare staff create files that are easily viewed by doctors and patients alike but administrators can also set key permissions around editing, annotating, and printing to ensure information remains secure. File format conversion with PrizmDoc Cloud APIs can help enhance patient portals with key features including:
- Easy combination of multiple files into single PDFs
- Data security with optional password protection
- Specific section or entire file conversion
- Searchable output formats
Relevant Watermarking
Last on our list of patient portal APIs is watermarking. By labeling key documents with unique healthcare watermarks, organizations can both improve front-line security and enhance HIPAA compliance. By training staff to only accept and process watermarked images and documents, companies can reduce the risk of potential compromise. If attackers attempt to spoof or modify key documents they can be easily detected because they won’t carry corporate watermarks. These marks also form a key component of auditing and data tracking if healthcare agencies are evaluated for HIPAA compliance by providing a visible chain of custody around document creation, storage, and access.
User-friendly patient portals are critical for healthcare companies to survive in the “new normal” — and embrace what comes next. But speedy access requires a robust security balance; document viewing, redaction, compression, conversion, and watermarking APIs from Accusoft can deliver privacy in practice and capitalize on patient portal potential. Try PrizmDoc Cloud API.

Software is everywhere. Recent research points to the development of “ubiquitous computing” solutions that underpin our interactions with familiar technologies and products. But there’s more to this IT evolution than meets the eye.
To meet growing consumer demand and corporate expectations of speed and security, enterprises are leveraging software development kits (SDKs) and application programming interfaces (APIs) — lightweight tools that can be easily integrated with existing applications and physical devices.
The result? A behind-the-curtain brand with powerful solutions. Did you know that you interact with Accusoft’s SDKs and APIs almost every day, but they’re hiding in plain sight?
Signed, Scanned, Delivered
Data is the foundation of reliable mail service. Accusoft’s Barcode Xpress Mobile (BXM) underpins critical technology used by the country’s largest mail carrier to ensure letters and packages are delivered to the right people on time, everytime.
By integrating BXM with mobile technology, employees can quickly scan postal barcodes to obtain delivery address, transit history, recipient names, and any special instructions for parcel drop-off or signature.
Accusoft’s SDK also empowers staff to deal with changing weather conditions like rain or snow, which may negatively affect packaging and transit labels. BXM has no trouble reading damaged, broken, or incorrect barcodes to ensure swift completion of appointed rounds.
Inside Job
Magnetic resonance imaging (MRI) machines provide critical data to healthcare providers about anatomical structures and physiological processes inside the human body without the need for invasive surgery. Now a fixture of both general and specialized hospitals across the United States, MRI machines depend on Accusoft’s PicTools Medical to create high-accuracy, high-quality images used to inform patient care.
Along with support for commercially-supported imaging software libraries, PicTools Medical natively delivers results that conform to digital imaging and communications in medicine (DICOM) image standards, making it easy for healthcare professionals to collaborate across departments, cities, or states and ensure patients receive the best care possible.
Green Machines
Used an ATM lately? Then you’ve probably watched ImagXpress at work. With over 80 functions for image processing and editing, ImagXpress provides ATM users with a fast, accurate view of the deposited check after the machine takes it.
Leveraging content processing technology, ImagXpress provides users with a better way to view their deposited check and keep an accurate depiction of their transaction for their records.
What does this mean for you, the consumer? ImagXpress streamlines the process that matters: documenting the check deposit with an image that shows the check you used in the transaction.
Behind the Scenes
Software streamlines our interaction with the world at large. But the cost and complexity of developing new software tools from the ground up for every new product and application can quickly sidetrack even the simplest of projects. The solution? Hide great code in plain sight with advanced SDKs and APIs.
Companies get the benefit of powerful tools and simplified functions fully integrated with existing applications and corporate security policies. Consumers reap the rewards of better end-user experience. Accurate, trackable mail delivery, life-saving medical images, and cold, hard cash on-demand. Ready to learn more about what Accusoft’s SDKs and APIs can do for you? Learn more about the products here.

The year was 1996. Dot-com was booming, Y2K loomed on the horizon, and Australia-based Outback Imaging needed adaptable software development toolkits (SDKs) to prototype a desktop imaging application capable of pushing scanned documents into popular EDRM systems without the need for manual import tools. They also needed a custom-built TWAIN UI to unify the customer experience without locking them into specific scanner brands.
In what one can only imagine was a montage of classic search engine queries, the company sourced three likely candidates. Within six months, they found their front runner was Accusoft, and the partnership began.
In 2003, they rolled out their first commercial product, EzeScan. Today, the product does more than just document imaging — EzeScan now offers server-based automated task processing and browser-based document workflow and approval capable through Robotic Task Automation (RTA) 24/7/365 with no human intervention.
With B2B churn rates rising, Medium notes that “regardless of industry, customer retention is often many leaders’ main strategic objective given today’s highly competitive landscape.” What’s the secret to Accusoft and EzeScan’s ongoing, mutually beneficial relationship?
Thankfully, the answer isn’t a vague, inspirational quote. In fact, it’s possible to debrief this age-defying agreement with three key characteristics including scalability, simplicity, and support.
Document Imaging at Scale
For EzeScan to evolve from a digital imaging application to a document transformation powerhouse, Outback needed toolkits that operate seamlessly within a Microsoft IDE, enables easy deployment on Windows, and includes superior code examples and documentation.
After four months of building three prototypes, Outback selected Accusoft SDKs to help jumpstart EzeScan R&D and embrace the need for digital transformation at scale. Today, the company leverages Accusoft’s TWAIN, ISIS, and PDF tools along with their OCR, MICR, and ICR search engines to drive continual evolution in their application.
Avoiding Technical Debt
Outback now supplies software solutions to a global network of customers, enabling them to both “go digital” and leverage their digital information in a more meaningful way. But developing this worldwide reputation for quality components and actionable results required an SDK foundation that was easy to implement and simple to use.
Accusoft offered the ideal solution to their problem. Toolkits that are customizable, incredibly simple to integrate, and work as expected. For Outback, this meant the ability to easily test and maintain new code without worrying about technical debt building up behind the design team as they innovate.
You Need It? You Got It
As noted by the Harvard Business Review, responsiveness plays a critical role in the strength and stability of B2B relationships. Without ongoing, committed support for software and toolkits organizations often have no choice but to shift suppliers or run the risk of losing what they’ve built.
Support is an integral component of the Accusoft and Outback’s relationship. While problems rarely occur, when they do, these issues are prioritized and quickly remediated. The result? Both businesses come out ahead. B2B relationships rely on scalability, simplicity and support to stay afloat. Now in its 23rd year, the Outback and Accusoft partnership has never been stronger.

Apple’s Swift programming language has excellent support for working with and consuming native Objective-C APIs. That language, however, has little to no applicability outside of Apple’s platforms. You are likely to find that you need to rely on lower level interoperability features in order to interface with cross platform APIs which are most commonly implemented in C or C++.
C is usually the greatest common denominator between whatever language your API is or will be written in and Swift. If you want to consume an existing C API, or are implementing a new one which can be used from C, you will find that the process is considerably simpler than consuming an existing API designed for C++ or some other high level language. Calls to such higher level languages will need to be wrapped in a layer of C using whatever interoperability features are available there.
Even Objective-C APIs can sometimes find this step necessary. Apple’s compiler will generally allow you to include C++ features and syntax in Objective-C source code, but it does so by considering such files to be written in an additional language which you might be unaware you are even using: Objective-C++. For most purposes the difference is transparent, but the Swift compiler is not compatible with this superset of Objective-C and you will need to generate header files for your API which do not include anything outside of the base Objective-C specification.
Once you have access to C compatible header files for your API there are two main factors that you will have to contend with to use them from Swift or to create an idiomatic Swift layer: type compatibility and memory management.
Integral Types
Integers are among the simplest types in any programming language, but there are a dazzling array of integer types. Many of these types have different widths in different platforms and contexts.
If you are using Swift 6 or later, you can utilize a set of C interoperability types which are now included in the Swift standard library. Additional documentation can now be found at that location on some of the other topics covered here. Swift’s Int and UInt types will be the same widths as C’s long and unsigned long in most cases but you should usually prefer to use the C interoperability types in Swift when available.
An even better option is to not use types whose widths are implementation defined. Swift presents a set of integer types with exact lengths which are detailed below, along with their counterparts from C’s stdint.h header.
Enumerations
Enumerations are ever present in APIs for good reason. Swift code can make use of C enumerations in included headers natively, but both C++ and Swift provide fuller featured enumeration types. These types offer better safety guarantees and a wider variety of backing types. Writing corresponding enum definitions in respective files is relatively straight forward:
barcode-type.swift
public enum SwiftBarcodeType: UInt64 {
case Barcode1D = 0
case Barcode2D = 1
case BarcodePostal = 2
}barcode-type.hpp
enum class CppBarcodeType: uint64_t
{
case Barcode1D = 0
case Barcode2D = 1
case BarcodePostal = 2
};barcode-type.h
typedef CBarcodeType uint64_t;You can then convert Swift enumeration values back and forth between UInt64’s like this:
public func getSwiftEnum(val: UInt64)->SwiftBarcodeType {
return SwiftBarcodeType(rawValue: val)
}
public func getRawValue(val: SwiftBarcodeType)->UInt64 {
return val.rawValue
}And similarly in C++:
CppBarcodeType getCppEnum(uint64_t val){
return CppBarcodeType{val};
}
uint64_t getRawValue(CppBarcodeType val){
Return static_cast(val);
}Structs and Pointers
Basic structs defined in C header files will be usable as is and can be passed to and from Swift code as values. If you need to pass pointers to and from C APIs, or if your structs contain pointers, Swift will do its best to translate them into one of its equivalent types, of which there are more than a few.
Opaque Pointers
Pointers to types which are declared in your C headers but not defined will be translated by Swift into its OpaquePointer class. Without the definitions present there is not much you can do to them in Swift other than store them and pass them back to the API.
Unsafe Pointers
Pointers to objects which Swift can represent (such as primitives or structs) will be represented in Swift by a set of generics, UnsafePointer<> and UnsafeMutablePointer<>. When pointing to C arrays of these objects, there are buffer versions of each of them: UnsafeBufferPointer<> and UnsafeMutableBufferPointer<>. Finally, all four of these types have an associated “raw” version which is not generic and is equivalent to C’s void*s: UnsafeRawPointer, etc.
UnsafeBufferPointer
UnsafeMutableBufferPointer
UnsafeRawBufferPointer
UnsafeRawMutableBufferPointer
These types will allow you to work with memory allocated in C or C++ and passed to Swift, but no automatic memory management or garbage collection will be performed on the memory they point to. They are essential for passing data from native code to Swift but you should be careful to make sure that any objects are deallocated after you are done with them.
Special Cases
Swift provides several special cases for passing objects to C APIs that make some common situations considerably easier:
- Swift strings are automatically converted when passed to functions declared as accepting char* arguments.
- Swift arrays can be passed to functions expecting pointer arguments of the equivalent type.
- Swift functions and closures can be passed to C API functions expecting function pointer arguments.
In the cases of arrays and functions you will of course have to ensure that their component types are compatible with what the C function expects.
Passing Memory Managed Objects to C
As mentioned above, there are several ways to pass pointers to Swift objects to C, but this is where some additional issues with memory management come into play. When passing objects which are dynamically allocated, you run the very real risk of passing data into your API which will no longer exist by the time it is used. Thankfully, the Unmanaged class provides some tools for these situations.
Unmanaged provides two static functions for creating instances from Swift objects: Unmanaged.passRetained() and Unmanaged.passUnretained(). The difference between the two is how the memory manager deals with the object your are creating the pointer from. Use passRetained if the C API will need to hold onto the reference for later use, but be warned that you will eventually need to manually release the object.
Once you have created an Unmanaged instance from either of these functions, you can use its toOpaque() method to yield an UnsafeMutableRawPointer which can be passed to a C function.